publications
publications by categories in reversed chronological order.
Under review (not listed in the publications below): 1 paper submitted to ICML 2025, 1 paper submitted Pattern Recognition, 1 paper submitted to IEEE Transactions on Artificial Intelligence.
2025
-
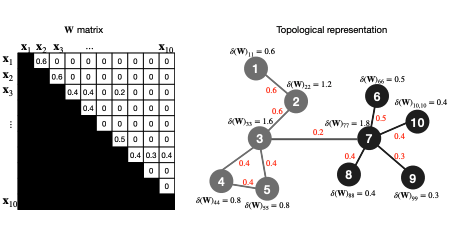 Towards Robust Nonlinear Subspace Clustering: A Kernel Learning ApproachKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2501.06368, 2025
Towards Robust Nonlinear Subspace Clustering: A Kernel Learning ApproachKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2501.06368, 2025Kernel-based subspace clustering, which addresses the nonlinear structures in data, is an evolving area of research. Despite noteworthy progressions, prevailing methodologies predominantly grapple with limitations relating to (i) the influence of predefined kernels on model performance; (ii) the difficulty of preserving the original manifold structures in the nonlinear space; (iii) the dependency of spectral-type strategies on the ideal block diagonal structure of the affinity matrix. This paper presents DKLM, a novel paradigm for kernel-induced nonlinear subspace clustering. DKLM provides a data-driven approach that directly learns the kernel from the data’s self-representation, ensuring adaptive weighting and satisfying the multiplicative triangle inequality constraint, which enhances the robustness of the learned kernel. By leveraging this learned kernel, DKLM preserves the local manifold structure of data in a nonlinear space while promoting the formation of an optimal block-diagonal affinity matrix. A thorough theoretical examination of DKLM reveals its relationship with existing clustering paradigms. Comprehensive experiments on synthetic and real-world datasets demonstrate the effectiveness of the proposed method.
@article{xu2025Towards, title = {Towards Robust Nonlinear Subspace Clustering: A Kernel Learning Approach}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, journal = {arXiv preprint arXiv:2501.06368}, year = {2025}, } -
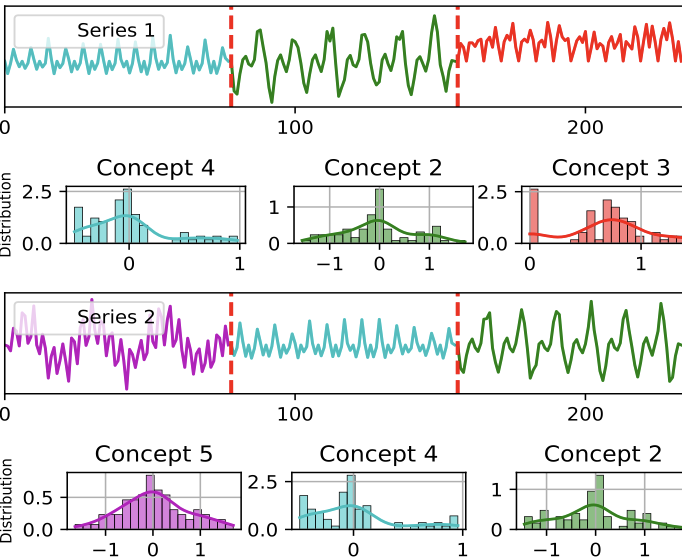 CORAL: Concept Drift Representation Learning for Co-evolving Time-seriesKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2501.01480, 2025
CORAL: Concept Drift Representation Learning for Co-evolving Time-seriesKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2501.01480, 2025In the realm of time series analysis, tackling the phenomenon of concept drift poses a significant challenge. Concept drift – characterized by the evolving statistical properties of time series data, affects the reliability and accuracy of conventional analysis models. This is particularly evident in co-evolving scenarios where interactions among variables are crucial. This paper presents CORAL, a simple yet effective method that models time series as an evolving ecosystem to learn representations of concept drift. CORAL employs a kernel-induced self-representation learning to generate a representation matrix, encapsulating the inherent dynamics of co-evolving time series. This matrix serves as a key tool for identification and adaptation to concept drift by observing its temporal variations. Furthermore, CORAL effectively identifies prevailing patterns and offers insights into emerging trends through pattern evolution analysis. Our empirical evaluation of CORAL across various datasets demonstrates its effectiveness in handling the complexities of concept drift. This approach introduces a novel perspective in the theoretical domain of co-evolving time series analysis, enhancing adaptability and accuracy in the face of dynamic data environments, and can be easily integrated into most deep learning backbones.
@article{xu2025drift2matrix, title = {CORAL: Concept Drift Representation Learning for Co-evolving Time-series}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, journal = {arXiv preprint arXiv:2501.01480}, year = {2025}, }


2024
-
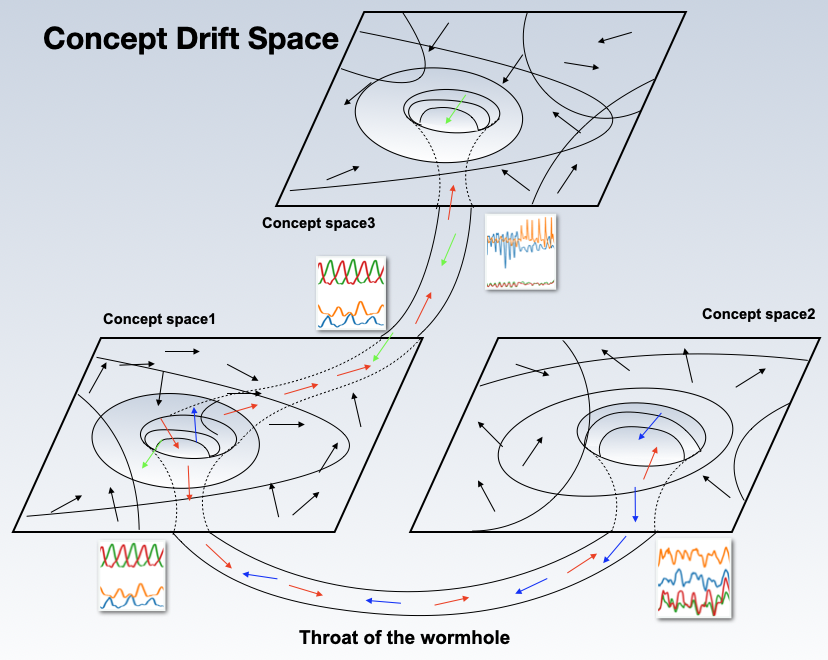 KAN4Drift: Are KAN Effective for Identifying and Tracking Concept Drift in Time Series?Kunpeng Xu, Lifei Chen, and Shengrui WangIn NeurIPS Workshop on Time Series in the Age of Large Models, 2024
KAN4Drift: Are KAN Effective for Identifying and Tracking Concept Drift in Time Series?Kunpeng Xu, Lifei Chen, and Shengrui WangIn NeurIPS Workshop on Time Series in the Age of Large Models, 2024Dynamic concepts in time series are crucial for understanding complex systems such as financial markets, healthcare, and online activity logs. These concepts help reveal structures and behaviors in sequential data for better decision-making and forecasting. Existing models struggle with detecting and tracking concept drift due to limitations in interpretability and adaptability. This paper introduces Kolmogorov-Arnold Networks (KAN) into time series and proposes WormKAN, a KAN-based auto-encoder to address concept drift in co-evolving time series. WormKAN integrates the KAN-SR module, in which the encoder, decoder, and self-representation layer are built on KAN, along with a temporal constraint to capture concept transitions. These transitions, akin to passing through a "wormhole", are identified by abrupt changes in the latent space. Experiments show that KAN and KAN-based models (WormKAN) effectively segment time series into meaningful concepts, enhancing the identification and tracking of concept drifts.
@inproceedings{xu2024kan4drift, title = {KAN4Drift: Are KAN Effective for Identifying and Tracking Concept Drift in Time Series?}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, booktitle = {NeurIPS Workshop on Time Series in the Age of Large Models}, year = {2024}, } -
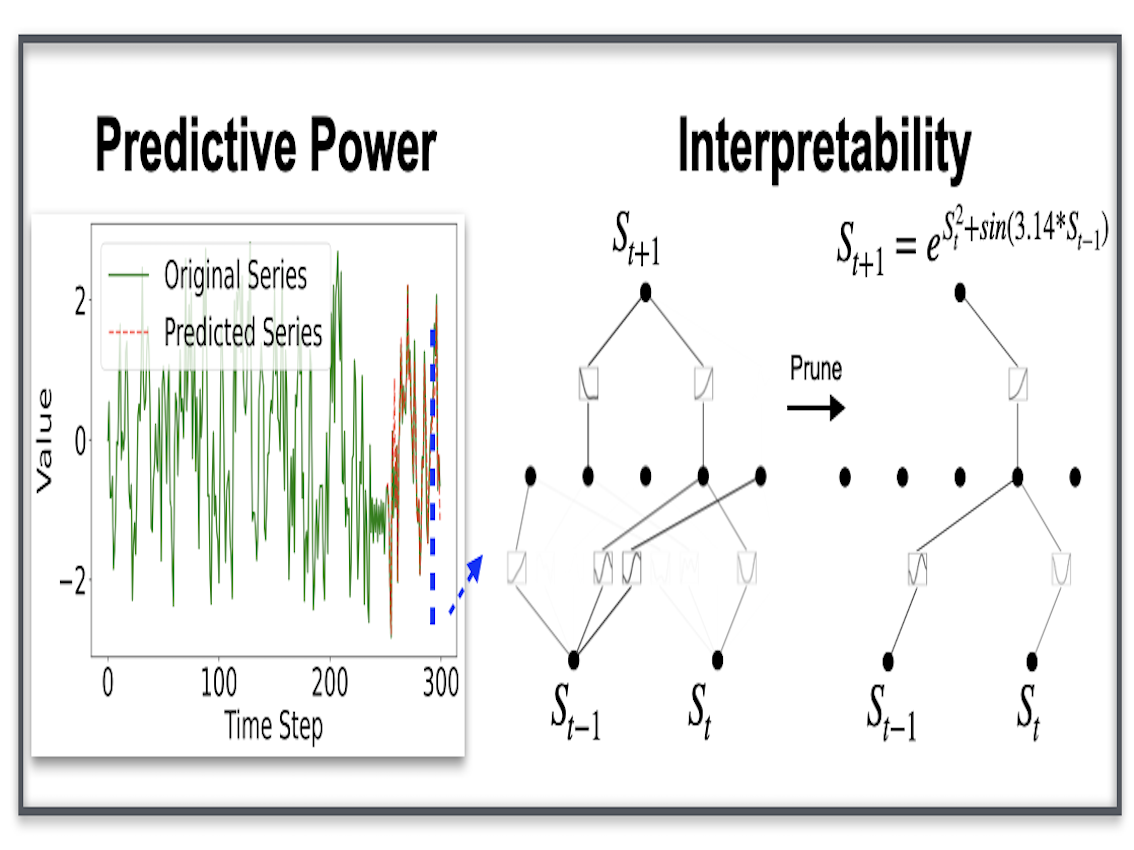 Kolmogorov-Arnold Networks for Time Series: Bridging Predictive Power and InterpretabilityKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2406.02496, 2024
Kolmogorov-Arnold Networks for Time Series: Bridging Predictive Power and InterpretabilityKunpeng Xu, Lifei Chen, and Shengrui WangarXiv preprint arXiv:2406.02496, 2024Kolmogorov-Arnold Networks (KAN) is a groundbreaking model recently proposed by the MIT team, representing a revolutionary approach with the potential to be a game-changer in the field. This innovative concept has rapidly garnered worldwide interest within the AI community. Inspired by the Kolmogorov-Arnold representation theorem, KAN utilizes spline-parametrized univariate functions in place of traditional linear weights, enabling them to dynamically learn activation patterns and significantly enhancing interpretability. In this paper, we explore the application of KAN to time series forecasting and propose two variants: T-KAN and MT-KAN. T-KAN is designed to detect concept drift within time series and can explain the nonlinear relationships between predictions and previous time steps through symbolic regression, making it highly interpretable in dynamically changing environments. MT-KAN, on the other hand, improves predictive performance by effectively uncovering and leveraging the complex relationships among variables in multivariate time series. Experiments validate the effectiveness of these approaches, demonstrating that T-KAN and MT-KAN significantly outperform traditional methods in time series forecasting tasks, not only enhancing predictive accuracy but also improving model interpretability. This research opens new avenues for adaptive forecasting models, highlighting the potential of KAN as a powerful and interpretable tool in predictive analytics.
@article{xu2024kolmogorov, title = {Kolmogorov-Arnold Networks for Time Series: Bridging Predictive Power and Interpretability}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, journal = {arXiv preprint arXiv:2406.02496}, year = {2024}, } -
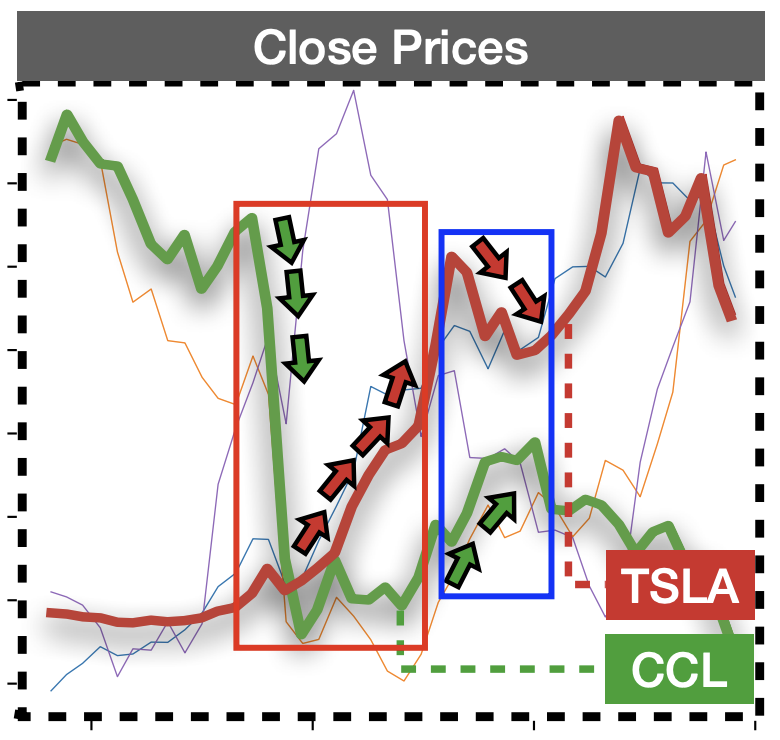 RHINE: A Regime-Switching Model with Nonlinear Representation for Discovering and Forecasting Regimes in Financial MarketsKunpeng Xu, Lifei Chen, Jean-Marc Patenaude, and 1 more authorIn Proceedings of the 2024 SIAM International Conference on Data Mining (SDM), 2024
RHINE: A Regime-Switching Model with Nonlinear Representation for Discovering and Forecasting Regimes in Financial MarketsKunpeng Xu, Lifei Chen, Jean-Marc Patenaude, and 1 more authorIn Proceedings of the 2024 SIAM International Conference on Data Mining (SDM), 2024We investigate the problem of discovering and forecasting regular regime switches in a financial ecosystem comprising multiple time series. Such regime switches, indicative of varying market behaviors across distinct time intervals, are pivotal for a nuanced understanding of market dynamics, which in turn allows informed model selection for forecasting and enhanced interpretability of predictive outcomes. Despite strides in this domain, prevailing methodologies often falter due to: (1) an inability to effectively model the temporal behaviors inherent in financial series; and (2) neglecting the interdependencies among series when discovering regimes. In this paper, we propose RHINE, a Regime-switcHIng model with Nonlinear rEpresentation. RHINE stands out with its kernel-based representation, adept at capturing the dynamic shifts in market regimes. This representation encapsulates the nonlinear interplay across multiple financial time series. By leveraging the kernel representation, we introduce an eigengap thresholding measure, designed to automatically discern the optimal number of financial market regimes, enhancing the model’s adaptability to market fluctuations. Empirical assessments on both synthetic and real-world stock market datasets underscore RHINE’s prowess. The findings illuminate that the inherent structures governing financial market behaviors are dynamic, and harnessing these dynamics via RHINE leads to a regime-based model that outperforms both conventional and state-of-the-art neural network models in predictive capabilities.
@inproceedings{xu2024rhine, title = {RHINE: A Regime-Switching Model with Nonlinear Representation for Discovering and Forecasting Regimes in Financial Markets}, author = {Xu, Kunpeng and Chen, Lifei and Patenaude, Jean-Marc and Wang, Shengrui}, booktitle = {Proceedings of the 2024 SIAM International Conference on Data Mining (SDM)}, pages = {526--534}, year = {2024}, organization = {SIAM}, } -
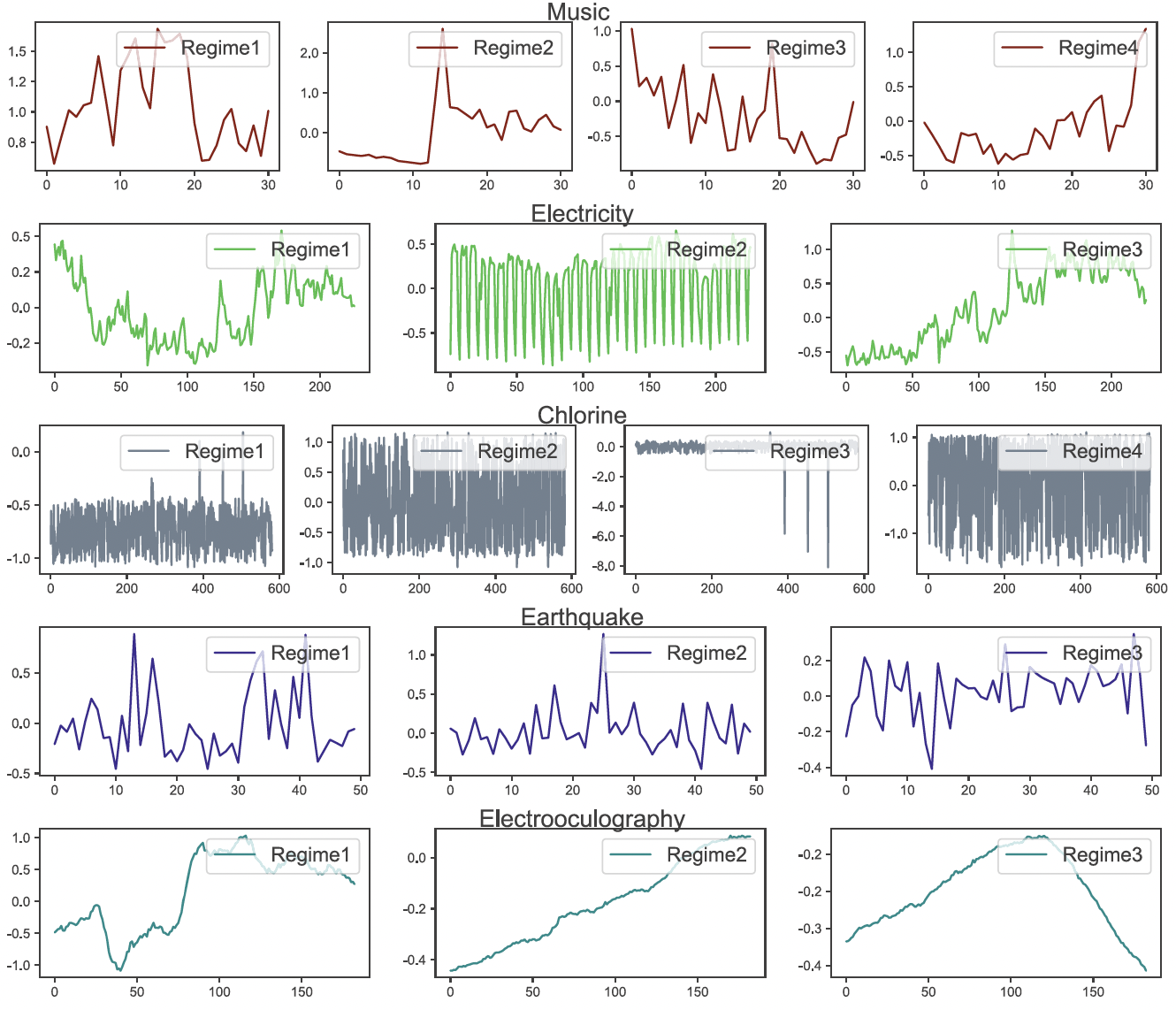 Kernel Representation Learning with Dynamic Regime Discovery for Time Series ForecastingKunpeng Xu, Lifei Chen, Jean-Marc Patenaude, and 1 more authorIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2024
Kernel Representation Learning with Dynamic Regime Discovery for Time Series ForecastingKunpeng Xu, Lifei Chen, Jean-Marc Patenaude, and 1 more authorIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2024Correlations between variables in complex ecosystems such as weather and financial markets lead to a great amount of dynamic and co-evolving time series data, posing a significant challenge to the current forecast methods. Discovering dynamic patterns (aka regimes) is crucial to an accurate forecast, especially for the interpretability of the outcome. In this paper, we develop a kernel-based method to learn effective representations for capturing dynamically changing regimes. Each such representation accounts for the non-linear interactions among multiple time series, thereby facilitating more effective regime discovery. On the basis of regime information, we build a regression model to forecast all the variables simultaneously for the next multiple time points. The results on six real-life datasets demonstrate that our method can yield the most accurate forecast (with the lowest root mean square error) in comparison with seven predictive models.
@inproceedings{xu2024kernel, title = {Kernel Representation Learning with Dynamic Regime Discovery for Time Series Forecasting}, author = {Xu, Kunpeng and Chen, Lifei and Patenaude, Jean-Marc and Wang, Shengrui}, booktitle = {Pacific-Asia Conference on Knowledge Discovery and Data Mining}, pages = {251--263}, year = {2024}, organization = {Springer}, } -
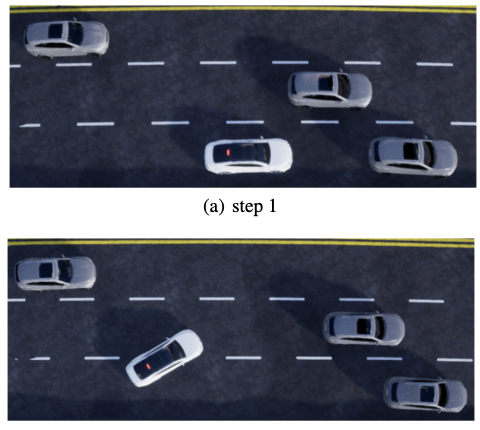 DRNet: A Decision-Making Method for Autonomous Lane Changing with Deep Reinforcement LearningKunpeng Xu, Lifei Chen, and Shengrui WangProceedings of the Canadian Conference on Artificial Intelligence, May 2024https://caiac.pubpub.org/pub/tcdsxqnh
DRNet: A Decision-Making Method for Autonomous Lane Changing with Deep Reinforcement LearningKunpeng Xu, Lifei Chen, and Shengrui WangProceedings of the Canadian Conference on Artificial Intelligence, May 2024https://caiac.pubpub.org/pub/tcdsxqnhMachine learning techniques have outperformed many rule-based methods for the decision-making of autonomous vehicles. Despite recent efforts, lane changing remains a big challenge due to the slow learning rates and possibility of executing unsafe actions. To help improve the state-of-the-art, we propose to leverage emerging Deep Reinforcement learning (DRL) for laNE changing in Tactical level and present "’DRNet", a novel and highly efficient DRL-based framework that both enables a DRL agent to learn to drive by executing reasonable lane changing on simulated highways with an arbitrary number of lanes and overcomes limitations of inefficient learning rates in DRL. Furthermore, to obtain a safe policy for tactical decisionmaking, DRNet integrates ideas from safety verification, the most important of autonomous driving, to ensure that only safe actions are chosen at any time. With the setting of our state representation and reward function, the trained agent is able to take appropriate actions in a real-world-like simulator. Our DRL agent has the ability to learn the desired task without causing collisions and outperforms DDQN and other baseline models.
@article{Xu2024DRNet, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, journal = {Proceedings of the Canadian Conference on Artificial Intelligence}, year = {2024}, month = may, note = {https://caiac.pubpub.org/pub/tcdsxqnh}, publisher = {Canadian Artificial Intelligence Association (CAIAC)}, title = {DRNet: A {Decision}-{Making} {Method} for {Autonomous} {Lane} {Changing} with {Deep} {Reinforcement} {Learning}}, }





2022
-
 Data-driven Kernel Subspace Clustering with Local Manifold PreservationKunpeng Xu, Lifei Chen, and Shengrui WangIn 2022 IEEE International Conference on Data Mining Workshops (ICDMW), May 2022
Data-driven Kernel Subspace Clustering with Local Manifold PreservationKunpeng Xu, Lifei Chen, and Shengrui WangIn 2022 IEEE International Conference on Data Mining Workshops (ICDMW), May 2022Kernel-based subspace clustering methods that can reveal the nonlinear structure of data are an emerging research topic. While advances have been made, existing methods suffer from one or both of the following shortcomings: (1) the predefined kernel determines their performance; (2) they may be vulnerable in arbitrary manifold subspace. In this paper, we propose a novel data-driven kernel subspace clustering model with local manifold preservation, named DKLM. Specifically, DKLM provides an explicit data-driven kernel learning strategy for learning kernel directly from the self-representation of data while satisfying the adaptive-weighting. Based on the kernel, DKLM allows preserving the local manifold structure of data through a kernel local manifold term in nonlinear space and encourages acquiring an affinity matrix with the optimal block diagonal. Various experiments on both synthetic data and real-world data demonstrate the effectiveness of our method.
@inproceedings{xu2022data, title = {Data-driven Kernel Subspace Clustering with Local Manifold Preservation}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, booktitle = {2022 IEEE International Conference on Data Mining Workshops (ICDMW)}, pages = {876--884}, year = {2022}, organization = {IEEE}, } -
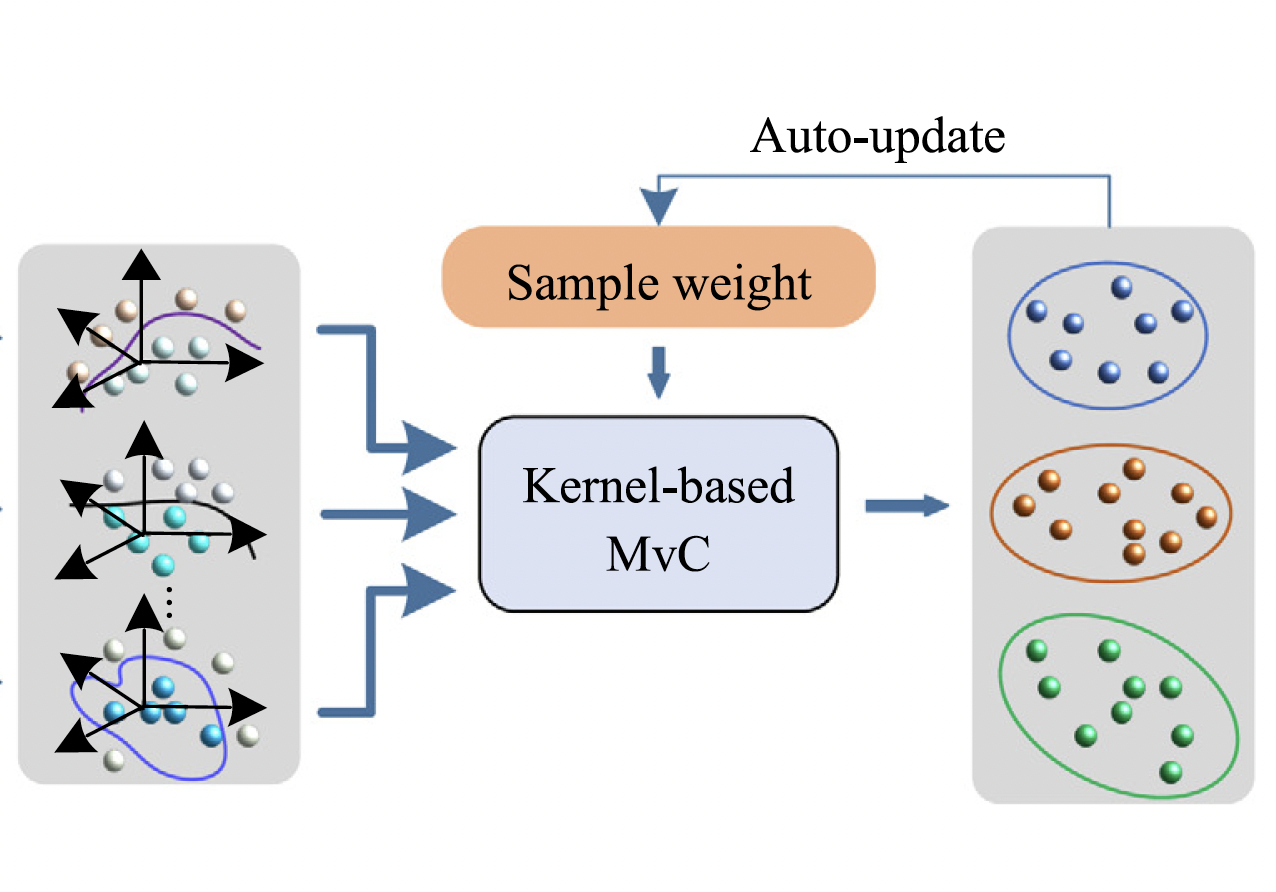 A Multi-view Kernel Clustering framework for Categorical sequencesKunpeng Xu, Lifei Chen, and Shengrui WangExpert Systems with Applications, May 2022
A Multi-view Kernel Clustering framework for Categorical sequencesKunpeng Xu, Lifei Chen, and Shengrui WangExpert Systems with Applications, May 2022Multi-view clustering, which optimally integrates complementary information from different views to improve clustering performance, has drawn considerable attention in recent years. Despite recent advances, issues remain when dealing with data of high dimensionality and heterogeneity, especially in categorical sequences. These unique challenges and properties have motivated us to develop a novel Multi-view Kernel Clustering framework for Categorical sequences (MKCC), where views are expressed in terms of kernel matrices and a weighted combination of the instances is learned in parallel to the partitioning. Concretely, MKCC adaptively constructs the kernel matrix without the need of defining the kernel function. Nonetheless, the computational cost of storing the kernel matrix is O(N^2). To address this issue, we integrate a simple and efficient method for approximating the kernel matrix. A new multi-view clustering algorithm and a cluster validity index for categorical sequences are also proposed based on the framework. An empirical analysis on synthetic data sets and several commonly used real-world data sets demonstrates the appropriateness of the proposal, with the results showing the method’s outstanding performance.
@article{xu2022multi, title = {A Multi-view Kernel Clustering framework for Categorical sequences}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui}, journal = {Expert Systems with Applications}, volume = {197}, pages = {116637}, year = {2022}, publisher = {Elsevier}, } -
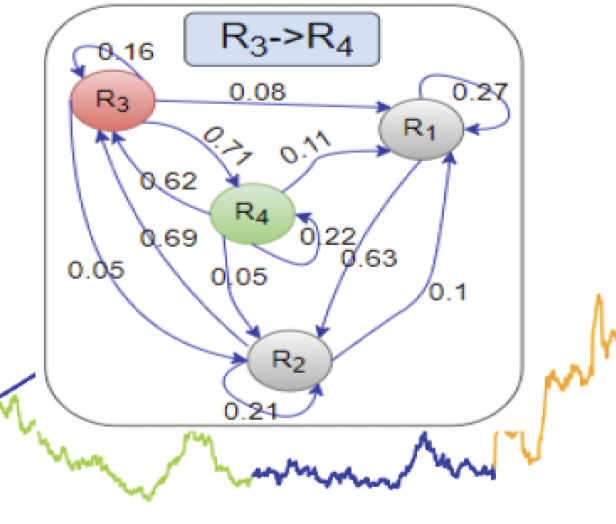 Clustering-based cross-sectional regime identification for financial market forecastingRongbo Chen, Mingxuan Sun, Kunpeng Xu, and 2 more authorsIn International Conference on Database and Expert Systems Applications, May 2022
Clustering-based cross-sectional regime identification for financial market forecastingRongbo Chen, Mingxuan Sun, Kunpeng Xu, and 2 more authorsIn International Conference on Database and Expert Systems Applications, May 2022Regime switching analysis is extensively advocated in many fields to capture complex behaviors underlying an ecosystem, such as the economic or financial system. A regime can be defined as a specific group of complex patterns that share common characteristics in a specific time interval. Regime switch, caused by external and/or internal drivers, refers to the changing behaviors exhibited by a system at a specific time point. The existing regime detection methods suffer from two drawbacks: they lack the capability to identify new regimes dynamically or they ignore the cross-sectional dependencies exhibited by time series data for the forecasting. This promoted us to devise a clusterbased regime identification model that can identify cross-sectional regimes dynamically with a time-varying transition probability, and capture cross-sectional dependencies underlying financial time series for market forecasting. Our approach makes use of a nonlinear model to account for the cross-sectional regime dependencies, neglected by most existing studies, that can improve the performance of a forecasting model significantly. Experimental results on both synthetic and real-world dataset demonstrate that our model outperforms state-of-the-art forecasting models.
@inproceedings{chen2022clustering, title = {Clustering-based cross-sectional regime identification for financial market forecasting}, author = {Chen, Rongbo and Sun, Mingxuan and Xu, Kunpeng and Patenaude, Jean-Marc and Wang, Shengrui}, booktitle = {International Conference on Database and Expert Systems Applications}, pages = {3--16}, year = {2022}, organization = {Springer}, } -
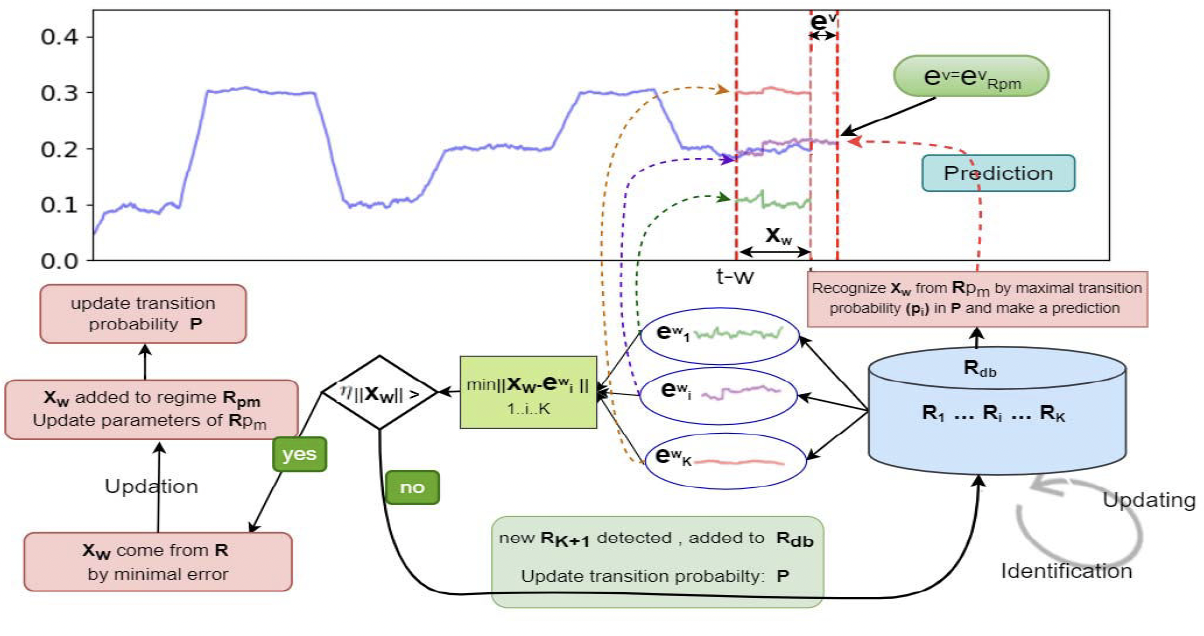 Dynamic Cross-sectional Regime Identification for Financial Market PredictionRongbo Chen, Kunpeng Xun, Jean-Marc Patenaude, and 1 more authorIn 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), May 2022
Dynamic Cross-sectional Regime Identification for Financial Market PredictionRongbo Chen, Kunpeng Xun, Jean-Marc Patenaude, and 1 more authorIn 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), May 2022We investigate issues related to dynamic cross-sectional regime identification for financial market prediction. A financial market can be viewed as an ecosystem regulated by regimes that may switch at different time points. In most existing regime-based prediction models, regimes can only switch, according to a static transition probability matrix, among a fixed set of regimes identified on training data due to the fact that they lack in mechanism of identifying new regimes on test data. This prevents them from being effective as the financial markets are time-evolving and may fall into a new regime at any future time. Moreover, most of them only handle single time series, and are not capable of dealing with multiple time series. These shortcomings prompted us to devise a dynamic cross-sectional regime identification model for time series prediction. The new model is defined on a multi-time-series system, with time-varying transition probabilities, and can identify new cross-sectional regimes dynamically from the time-evolving financial market. Experimental results on realworld financial datasets illustrate the promising performance and suitability of our model.
@inproceedings{chen2022dynamic, title = {Dynamic Cross-sectional Regime Identification for Financial Market Prediction}, author = {Chen, Rongbo and Xun, Kunpeng and Patenaude, Jean-Marc and Wang, Shengrui}, booktitle = {2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC)}, pages = {295--300}, year = {2022}, organization = {IEEE}, }




2018
-
 A self-representation model for robust clustering of categorical sequencesKunpeng Xu, Lifei Chen, Shengrui Wang, and 1 more authorIn Web and Big Data: APWeb-WAIM 2018 International Workshops: MWDA, BAH, KGMA, DMMOOC, DS, Macau, China, July 23–25, 2018, Revised Selected Papers 2, May 2018
A self-representation model for robust clustering of categorical sequencesKunpeng Xu, Lifei Chen, Shengrui Wang, and 1 more authorIn Web and Big Data: APWeb-WAIM 2018 International Workshops: MWDA, BAH, KGMA, DMMOOC, DS, Macau, China, July 23–25, 2018, Revised Selected Papers 2, May 2018Robust clustering on categorical sequences remains an open and challenging task due to the noise data and lack of an inherently meaningful measure of pairwise similarity between sequences. In this paper, a self-representation model is proposed as a representation of categorical sequences. Based on the model, we transform the robust clustering to a subspace clustering problem. Furthermore, an efficient algorithm for robust clustering of categorical sequences is also proposed, which provides the new measure with high-quality clustering results and the elimination of noise sequences using the subspace method. The experimental results on the synthetic and real world data demonstrate the promising performance of the proposed method.
@inproceedings{xu2018self, title = {A self-representation model for robust clustering of categorical sequences}, author = {Xu, Kunpeng and Chen, Lifei and Wang, Shengrui and Wang, Beizhan}, booktitle = {Web and Big Data: APWeb-WAIM 2018 International Workshops: MWDA, BAH, KGMA, DMMOOC, DS, Macau, China, July 23--25, 2018, Revised Selected Papers 2}, pages = {13--23}, year = {2018}, organization = {Springer}, }
